


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
長谷川 雄太; 小野寺 直幸; 井戸村 泰宏
no journal, ,
原子力機構におけるCityLBMプロジェクトでは、AMR(Adaptive mesh refinement; 適合細分化格子法)に基づく実時間都市風況予測コードの開発を行ってきた。次世代のCityLBMコードにおいては、予測の信頼性を向上するためにアンサンブル計算の導入が求められている。このためには、メモリ使用量を1つの計算あたり1ノードないし4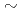 16GPUの規模に抑える必要がある。本研究では、AMRコードにおけるメモリ使用量の削減およびデータ通信の高速化を目的として、CUDAのUnified Memoryを用いたイントラノード複数GPU計算の実装を試行した。Unified MemoryへのアクセスがHBM2(同一GPU)またはNVLink(隣接GPU)から自動的に判別されるため、比較的簡便に複数GPU計算を実装することができる。等間隔格子上で3次元拡散方程式および格子ボルツマン法の複数GPU計算コードを実装し、弱スケーリングおよび強スケーリングを測定することでNVLinkの性能テストを行った。
16GPUの規模に抑える必要がある。本研究では、AMRコードにおけるメモリ使用量の削減およびデータ通信の高速化を目的として、CUDAのUnified Memoryを用いたイントラノード複数GPU計算の実装を試行した。Unified MemoryへのアクセスがHBM2(同一GPU)またはNVLink(隣接GPU)から自動的に判別されるため、比較的簡便に複数GPU計算を実装することができる。等間隔格子上で3次元拡散方程式および格子ボルツマン法の複数GPU計算コードを実装し、弱スケーリングおよび強スケーリングを測定することでNVLinkの性能テストを行った。